Did you know that memory is slow compared to CPU? I kinda knew too but recently I've got a revelation from two unrelated sources about how it affects design of programming languages. I also learned about a new thing called "value/reference type dichotomy".
I've stumbled upon this term while reading a preliminary review of Apple's Swift from Graydon Hoare, creator of Rust. I sent him an email asking about it and he replied with a wonderfully detailed explanation covering not only that but also memory, caches, garbage collection and simplicity of programming models of various languages. You gotta love Rust simply because of the fact that Graydon is such a terrific guy!
Allocation models
In a nutshell, there are two ways in which programming languages allocate variables:
-
Some use "uniform representation" when all variables allocated on the stack are of the same size: one machine word. This leads to scalar objects (ints, bools, etc.) being allocated directly on the stack and non-scalar objects being allocated automatically on the heap and represented on the stack by references. This is a value/reference type dichotomy. Java, C# (mostly), Python, Ruby are such languages.
-
Other languages allow objects of different type, size and complexity to be allocated directly on the stack and give programmers a choice where to keep things. C/C++, Go and Rust are such languages.
The catch with uniform stack languages is, while they hide a great deal of complexity from a programmer, they pay for it in performance. Because now instead of manipulating objects on the stack you always have to dereference pointers and look into main memory. It wasn't obvious to me that the penalty is significant though. "The stack" after all is just a software concept and it resides in the same physical memory as the heap, so theoretically you just have to make two memory lookups instead of one.
Cache matters
The practical difference is in cache locality. If you constantly push and pull values on the same stack it will be mostly in cache pretty much all the time. And some of those values will even be already in the CPU registers thanks to compiler optimizations. And on the other hand when you're constantly allocating and grabage-collecting things in random places in memory they're pretty much never going to be cached successfully. Graydon has quoted a number of 80% performance hit for Java code caused only by that. Yes, that's eighty percent!
Another confirmation of the same idea I've got from the presentation "Five things that make Go fast" by Dave Cheney. I don't know how to link to the relevant part within the page so you will have to read it in full :-). Which I recommend doing anyway, it's actually very clear and informative even if you don't know Go.
I'm only going to quote a picture from that presentation showing why this problem has "suddenly" started to bother language designers:
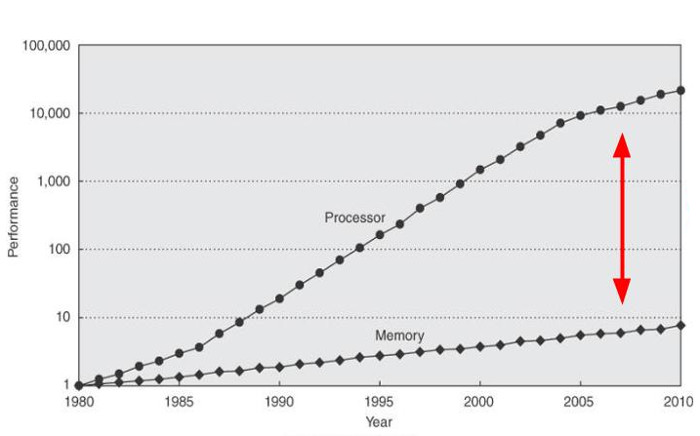
How about Python?
When Alex Gaynor tells us why Python is slow he specifically names three main culprits for the performance hit: hash lookups, allocations, copying. When talking about allocations he mostly focuses on the fact that idiomatic Python forces an interpreter to do a lot of them, and the secret of getting better performance is to provide APIs that don't require as many.
However it turns out that it also matters where all those allocations happen. Alex claims that PyPy in particular by now has learned how to allocate really efficiently, so I wonder if it's by any chance smart enough to do it on the stack?
Comments: 3
Go has a choice where to store data, but this choice not exposed to programmer. Anything may be allocated on stack or heap depending on size and escape analysis.
Proof: The language spec http://golang.org/ref/spec does not mention "stack" or "heap".
http://stackoverflow.com/questions/10866195/stack-vs-heap-allocation-of-structs-in-go-and-how-they-relate-to-garbage-collec
https://groups.google.com/forum/#!topic/golang-nuts/0ec6hawwWQ0
Yeah, I should've written: "and some of them give programmers a choice". Thanks!
Viva la cache-oblivious algorithms!