Сегодня в Django'вском списке рассылки вычитал об одной штуке, которая неочевидна из документации, но тем не менее дико крута. Нельзя такое прятать!
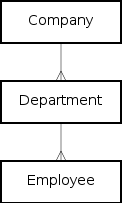
У вас в базе есть 3 таблички: Компания, Отдел и Сотрудник, которые последовательно связаны друг с другом отношениями один-ко-многим: совершенно обычная и часто встречающаяся модель. В Django это описывается примерно так:
class Company(meta.Model):
name=meta.CharField(maxlength=20)
class Department(meta.Model):
company=meta.ForeignKey(Company)
name=meta.CharField(maxlength=20)
class Employee(meta.Model):
department=meta.ForeignKey(Department)
name=meta.CharField(maxlength=20)
И нам нужны все сотрудники какой-то определенной компании. Поскольку у Сотрудника нет прямой ссылки на Компанию, придется объединить таблички, и достать Компанию через Отдел.
Если делать SQL'ом, то это, очевидно, выглядит как-то так:
SELECT
employees.id, employees.name
FROM
employees, departments
WHERE
department_id=departments.id AND
company_id=1
Несмотря на то, что все просто, такие ссылки через таблицы добавляют очень много мусора в SQL, и эти запросы потом трудно разбирать: не сразу видно, какие таблички в запросе интересны, а какие просто вспомогательные для ссылок.
Но в Django есть API доступа к БД, который, по идее, должен это упрощать. Из документации прямо следует только то, что можно автоматически получить непосредственно связанные объекты (например company.get_department_list()), а вот через таблицу, вроде бы, нет средств. Но оказывается, можно:
employees.get_list(department__company__pk=1)
И все! Вот это "department__company" автоматически построит нужные join'ы. Очень, на мой взгляд, элегантно и читаемо.
А вот какой реальный SQL строится по этому вызову (я только отформатировал для удобства чтения):
SELECT
"test_employees"."id",
"test_employees"."department_id",
"test_employees"."name"
FROM
"test_employees",
"test_departments" "t1"
WHERE
"test_employees"."department_id" = "t1"."id" AND
"t1"."company_id" = 1
Комментарии: 4
Вообще-то я думаю что намного эффективнее будет запрос вида
Последнее условие (вместо AND) впрочем можно запихнуть в условие WHERE, если очень нравится.
Если уж гворить о "мусоре" в базе данных при join-ах, то здесь с точки зрения SQL составитель базы сам себе злобный буратина.
Из документации SQL явно следует (но никто на это пальцем не тыкает) что если есть в таблице два поля с одинаковым именем то конструкция NATURAL JOIN может объединить значения таблиц по этому полю (не забываем что запятая в списке таблиц на самом деле syntactic sugar для INNER JOIN).
Почему этим никто не пользуется?
Очень просто. Многие хорошие разработчики в основном знакомы с базами постольку-поскольку и тяготеют к написанию конструкций типа (пример для postgreSQL)
Это и приводит к построению запросов через декартово произведение с фильтрацией =>