Это долгожданное (в основном мной :-) ) продолжение статьи "Контролируемое скачивание", где я писал про то, как я реализовывал скачивание с авторизацией, контролем скорости и успешного завершения в Неком Музыкальном Сервисе. Сервис мы запустили в конце декабря в работу, и о нем у меня будет еще, что написать в самое ближайшее время. Но сейчас я затрону только тот момент, как же там на самом деле работает контролируемое скачивание...
Я буду исходить из того, что вы читали первую часть триллера. Если нет, почитайте сейчас, потому что иначе ничего не поймете. А если читали, то все равно пробегитесь еще разок, потому что давно это было :-).
Напомню вкратце, на какой схеме я остановился в прошлый раз.
- клиент обращается за скачиванием в Django-приложение, работающее под Apache'ем
- приложение возвращает в Apache умный итератор, из которого файл выдается пользователю
- умный итератор умеет ограничивать скорость, придерживая выдачу кусочков файла
- умный итератор учитывает количество отданных байт, записывая его в БД
И в таком виде оно работало у меня на домашней тестовой конфигурации между ноутбуком и настольным компьютером при скачке в пяток параллельных потоков. Также оно работало и на сервере, когда это тестировал я и еще пара человек.
А потом, как и положено по законам драматургии, пришли пользователи :-). Точнее, даже не столько пользователи, сколько нашему менеджеру проекта пришла в голову идея сымитировать небольшую нагрузку и скачать файл в 40 потоков на широком канале. Сервер встал. Загрузка сервера сильно взлетела и продолжала постоянно расти, и при этом сервер не обслуживал ни обычные веб-запросы, ни собственно скачивание. Клиентская качалка не получала никаких данных, ждала таймаут и пересоединялась, пересоединялась, пересоединялась... О чем и был заведен соответствующий баг.
Мыканье слепого котенка
Забегая вперед, скажу, что починка этого бага длилась с разной интенсивностью примерно столько же, сколько весь остальной проект. И практически все время состояла из опробования всяких разных идей, не имевших, как оказалось, никакого отношения к реальной проблеме. Но обо всем по порядку.
Попытка 1: во всем виноват mod_python!
Такое поведение сервера — огромная загрузка и ничего полезного — часто означает, что он только и делает, что свапится. "Ну конечно!" — подумал я, ведь все же знают, что mod_python, который рекомендуется для работы с Django, обладает этим самым минусом: кушает вместе с Апачем сравнительно много памяти. Значит, достаточно просто перевести сервер с Апача на lighttpd и завести Django-приложение через FastCGI, и проблема будет решена! Сказано — сделано. Никаких багов после перевода приложения на другую схему развертывания не возникло, но и не решило это ничего: сервер вел себя абсолютно также...
Попытка 2: утекание коннектов
Поняв, что "нахаляву" проблема не решилась, я стал тестировать приложение в домашних условиях и в какой-то момент поймал странную картину: через несколько секунд начала многопоточного скачивания на сервере образовывалось большое количество процессов Postgres'а — около 70 (по нормальному хватает минимальных 4, включая служебные). После небольшого расследования на поверхность был извлечен совершенно реальный баг. Django всегда закрывает соединение с БД сразу после завершения обработки запроса. Но для контроля скачивания я возвращаю из джанговской функции свой итератор, который начинает выполняться уже после того, как он из Django передан наверх, и соединение с БД к тому моменту уже закрыто и забыто. Но вот в процессе итераций я записываю статистику скачивания как раз в БД, для чего тут же снова автоматически открывается один новый коннект. А закрывать его автоматически уже некому. Вот они и плодились, занимая память.
Попытка 3: во всем виноват flup!
Но и после починки утекания соединений с БД поведение сервера все равно осталось тем же: полный ступор. Больше того, на тестах с одним скачивающим потоком появилась еще какая-то странная штука...
Тут надо дорассказать, что в Неком Музыкальном Сервисе все скачивание организовано через корзину: туда альбом сначала кладется, оттуда уже скачивается, и при успешном завершении скачивания из нее удаляется.
И вот, начинаю я скачивать альбом и через несколько секунд обрываю это дело, закрывая браузер. Пытаюсь смотреть на всякие логи, выдумывать идеи, и через несколько минут возвращаюсь к тесту опять. И тут вижу, что альбома в корзине... нет. Причем на третий раз стало понятно, что это не случайность, а самая настоящая мистика: я полностью обрубаю свою связь с сервером, а альбом там самостоятельно тихой сапой куда-то докачивается!!! Именно докачивается, а не сразу удаляется из корзины, потому что проходит какое-то время, прежде чем он оттуда удалится, и он еще эдак издевательски записывается в историю успешных скачиваний.
FastCGI-сервер с Django-приложением организуется с помощью библиотечки flup, задача которой — забрать у Django-приложения итератор с данными и выдать их веб-серверу через собственно FastCGI протокол. Так вот оказалось, что когда клиентский браузер обрывает соединение, lighttpd тоже обрывает соединение с flup и уходит заниматься другими запросами. А вот flup... Он-то совершенно игнорирует тот факт, что данные от него никто не принимает, и продолжает их исправно забирать у приложения и куда-то отдавать. И таким образом через какое-то время приложение думает, что скачивание прошло вполне успешно.

Помимо того, что такое поведение разрушает логику скачивания как таковую, я тут же решил, что это и есть причина ступора сервера: ведь раз flup забирает данные, то он их может складывать в какой-нибудь буфер, который занимает память, и так на каждом коннекте.
Через некоторое время с помощью магии "open source", электронной почты, английского языка и доброй воли автора flup Аллана Садди баг в flup был починен, и я с новыми надеждами запустил сервис в новое тестирование.
Попытка 4: nginx
Ага, вы правильно поняли — ни черта не изменилось :-). Находясь в легком отчаянии от полного непонимания, что вообще происходит (а ведь должно же работать!), я внял совету нашего менеджера проекта попробовать запустить сервис через веб-сервер nginx, который по слухам ещё меньше и быстрее lighttpd должен быть.
К слову о менеджере проекта... Он не от нечего делать вникал во всякие серверно-программерские дебри, а потому что всю дорогу выполнял еще и основную тестирующую нагрузку, потому что я тогда плотно сидел на диалапном соединении и при всем желании как следует нагрузить сервер через него не мог.
Какого же было мое удивление, когда в связке с nginx возникли приблизительно те же проблемы, что только что были починены на стороне flup. Только теперь уже сам nginx, агрессивно забирал содержимое из FastCGI-соединения, не заботясь о том, с какой скоростью принимает их клиент (и принимает ли вообще). В результате, из-за того, что nginx быстренько забирал у приложения все данные, альбом регистрировался успешно скачанным и изымался из корзины задолго до того, как клиент его скачивал. И с этого момента все новые запросы клиентского download-менеджера к другим кускам файла падали с ошибками, так как файла уже не существовало.

Правда на этот раз магия "open-source" мне не помогла. Игорь Сысоев — автор nginx — ответил в рассылке в том духе, что это старая мохнатая проблема, и если бы ее было просто починить, то давно уже починил бы... Так я вернулся к lighttpd.
Попытка 5: новый баг в lighty
Стоит заметить, что все это время, несмотря на такие разные причины неработы скачивания, внешне симптомы выглядели все время одинаково: download-менеджер соединяется несколькими потоками с сервером, сначала принимает какое-то количество данных, а потом все скачивание останавливается и он начинает беспрестанно пересоединяться, так ничего больше и не получая. Все это так долго выглядело как "сервер уходит в свап", что поначалу никто не обратил внимание на одну маленькую деталь. Некоторое количество данных принималось всегда в том коннекте, который запрашивал первый кусочек, расположенный в начале файла (это важно), а все последующие соединения отваливались как-то очень сразу, без особых потуг помучиться, там, подождать таймаут, как положено. Причем ситуация повторялась всегда.
После настойчивого тестирования и сравнения двух этих ситуаций я раскопал удивительный баг, на этот раз — в lighttpd. Засада оказалась — вы не поверите — в цифре кода статуса HTTP-ответа, выдаваемого моим приложением. Первый кусочек файла запрашивался самым обычным GET'ом, и получал в ответ самый обычный 200 OK, и с ним все было хорошо. А вот другие кусочки запрашивались с указанием диапазона нужных байтов, и в ответ получали другой код — 206 Partial content. И вот с ними-то lighttpd и глючил: если он получает из FastCGI сервера ответ со статусом 206, то отказывается принимать туловище дальше, а просто закрывает соединение. Вот так. И никакая "чрезмерная нагрузка" тут ни при чем.
Поискав (безуспешно) ответ на "почему" и "что делать", я снова обратился к магии "open source" и... да, полез искать правды в Сишный код lighty.
Что интересно, нашел! Вот кусочек, который мне подвернулся на глаза довольно быстро в connections.c:
case 206: /* write_queue is already prepared */
con->file_finished = 1;
break;Очень подозрительно, не правда ли? Я так и не знаю, зачем нужно было это условие, но после того, как я закомментировал этот "file_finished", а после еще научил mod_fastcgi.c, что "положительный ответ" в HTTP это не 200, а диапазон [200 - 299], баг ушел. И новые не пришли.
Попытка 6: долой БД!
Впрочем, Самый Главный Баг тоже никуда не делся. И следующая идея, которая была отработана до дна — это то, что записывание в БД статистики о состоянии скачивания каждым процессом на каждой итерации происходит сотни раз в секунду и должно тормозить. Сначала я попытался заменить запись строчек в БД на запись в некую общую область памяти на сервере, в качестве которой выступал memcached. А потом была еще опробована идея записывать эту статистику в файлы на диске.
В общем, ни одно из этих изменений не повлияло значительно на картину происходящего. То есть PostgreSQL с многопроцессным доступом вполне справлялся. Но в качестве исторического казуса стоит отметить, что именно решение с файлами осталось и работает по сю пору :-).
Попытки закончились
Я погрешу против истины, если скажу, что совсем ничего не исправилось... Нет, после правки утечек соединений с БД и скачиваний в никуда сервер стал кое-что качать. Но все равно, с реальной нагрузкой он совершенно не справлялся: 4 или 5 человек легко ставили его на колени.
Примерно на этом моменте, когда все сторонние эффекты были отброшены, у меня стало формироваться четкое представление о том, почему именно все так плохо.
Все, на самом деле, удивительно просто. Каждый Django-процесс — это Apache + mod_python + интерпретатор Питона + Django + мой код = 25 - 30 МБ. Под lighttpd с FastCGI чуть меньше — 18 - 22 МБ. А это значит, что для того, чтобы держать одновременно 100 пользователей (реальная необходимость) нужно от 2 до 3 ГБ свободной памяти без учета памяти на все остальное. А памяти тогда в сервере было 500 МБ... Вот вам и сваппинг. Причем добивание сервера памятью под завязку тоже не спасло бы, потому что помимо скачивания есть еще и закачивание, и весь остальной веб, так что там реально получалось куда больше 4 ГБ. Да и 100 пользователей были минимальным количеством, предполагалось и побольше.
Что самое печальное, все хорошие идеи на тот момент практически закончились. Был один запасной вариант вообще отказаться от всей идеи контролируемого скачивания как такового и оставить на сервере работать FTP-демон, который замечательно справляется со своими задачами. Больше того, у этого демона (proftpd) есть, вроде бы, какая-то возможность выполнять SQL, а значит, что теоретически его можно было бы даже заставить отмечать успешное скачивание, залезая напрямую в базу.
И еще в голове у меня крутилась совершенно дикая идея, которую я не рассказывал никому во избежание навлечь мрак полного отчаяния в и так-то невеселые времена (проект, между тем, задерживался уже месяца на два). А именно, написать свой веб-сервер на C++, вдохновившись успешно работающим proftpd, каждый процесс которого занимает по 1,5 МБ вместо 25.
То есть выбор остался такой: или полное поражение, или дурацкая авантюра, с большой вероятностью ведущая к такому же полному поражению через неделю.
Как ни странно, я все же решил попробовать написать свой веб-сервер :-). В конце концов, недели мне точно должно было хватить, чтобы понять, срастется оно или нет. И я приступил с расспросами к Google на предмет того, "как там пишутся демоны на C++", на котором я ничего не писал уже несколько лет.
"Медуза"
Но провидению было угодно, чтобы нагуглил я совсем не то, что искал. Рыская вокруг результатов со словами "fork", "daemon", "web server" и всего такого я вдруг заметил знакомое слово "Python" и наткнулся на страничку, которая, ни много ни мало, открыла мне совершенно незнакомую доселе парадигму массового обслуживания запросов и стала поворотной вехой во всей этой истории.
Эта страничка — ныне уже не вполне актуальное описание питоновской библиотеки "Medusa", которая как раз и предназначена для создания серверов, обслуживающих большое количество клиентов. А неактуально оно по той причине, что ядро библиотечки этой, как оказалось, уже давно включено в стандартную библиотеку Питона в виде неприметных модулей asyncore и asynchat.
И вот про эту самую "новую парадигму" я хочу написать подробней. Заранее извиняюсь за отнятое время перед теми, кому она давно уже не нова. Поделюсь с теми, кто так же темен, как я :-).
Оказывается, существует три распространенных подхода к обслуживанию одни сервером нескольких одновременных запросов к серверу. Первые два широко известны:
Многопроцессный, когда сервер для обработки запросов плодит копии (fork'ается), каждая из которых изолирована в памяти и независима от соседних процессов. Это наиболее популярный метод в юникс-средах, потому что fork сравнительно дешев, а треды не везде реализованы хорошо и тормозят. Кроме того, в том же Линуксе, если я правильно помню, именно изолированные процессы необходимы для работы PHP.
Основной проблеме этого способа было посвящено все предыдущее повествовавание: память расходуется много и пропорционально количеству запросов.
Многотредный, когда запросы обслуживаются несколькими тредами внутри одного или нескольких процессов. Этот метод популярен в Windows-средах, потому что создание новых процессов сравнительно дорого, а вот треды в Windows сделаны очень неплохо.
Впрочем, для приложений на Питоне это не рекомендуется в любом случае из-за Global Interpreter Lock.
Третий способ называется "асинхронное мультиплексирование с помощью неблокирующих сокетов". Здесь для обслуживания всех запросов достаточно одного процесса, который у себя открывает отдельные сокеты на каждый текущий запрос и обслуживает их по очереди, в одном большом цикле.
Но раз это один процесс, то пока он обслуживает один сокет (отправляет или принимает данные) остальные сокеты не обслуживает никто. И поэтому, по идее, достаточно одного медленного соединения, чтобы все тормозило в ожидании его. Но этого не происходит, потому что у всех современных ОС есть так называемый "неблокирующий" режим работы сокетов:
При записи в неблокирующий сокет процесс отдает ОС указатель на сокет, указатель на данные и говорит: "давай, отправляй". И дальше TCP/IP-стек ОС будет заниматься отправкой под управлением ядра совершенно самостоятельно, а управление в процесс возвращается мгновенно. Чтобы узнать, когда данные отправлены (или не отправлены), процесс может периодически проверять состояние сокета, когда оно снова изменится на "готов к записи".
Аналогично при чтении процесс периодически просматривает состояние сокета, в ожидании того, когда ОС сообщит, что там появились данные. После этого отдает ОС указатель на пустой буфер, говорит: "сваливай всё сюда". И может опять идти заниматься своими делами.
Другими словами, обслуживание сокета процессом происходит очень быстро, и именно поэтому он может быстро бегать по ним всем, каждый раз ставя на отправку или прием очередную порцию данных. А черновой неинтересной работой по перекладыванию байтов в провод и из провода занимается ОС, спасибо ей большое.
Но отсюда вытекает одно важное условие работы всей этой замечательной схемы. Работу по передаче данных забирает на себя ОС, но работу по подготовке этих данных все еще должна делать ваша программа. И пока она это делает для одного сокета, остальные действительно вынуждены ждать. Поэтому такой способ подходит только в том случае, если подготовка и обработка данных для каждого конкретного потребителя либо сама по себе очень быстра, либо может быть разбита на мелкие быстрые кусочки.
То есть, если сервер занимается, например, выдачей статических файлов, и для каждого кусочка файла ему надо только считать в память очередной буфер и перекинуть его в сокет — это очень быстро, и такой подход здесь идеально подходит. А вот если серверу для формирования кусочка контента надо долго напряженно копаться в БД или, скажем, зазиповывать архив или обрезать изображение размером 5000 на 3000 точек, то все остальные сокеты действительно будут долго ждать одного, и все будет тормозить. В этом случае надо искать способы разбить долгую задачу на несколько кусочков или передать ее на выполнение в другой процесс или тред.
Download server
Довольно быстро я понял, что это как раз то, что мне надо. Действительно, вся невеликая логика, которая мне нужна для обработки запроса — это авторизация пользователя по логину с паролем и арифметика ограничения скорости скачивания. Все это недолгие операции, а значит принципиально это работать должно.
Но самое, самое-то главное, что при наличии библиотек я могу написать это на Питоне, а значит — использовать Django! А значит в этом отдельном сервере скачивания смогу использовать всю свою уже имеющуюся логику авторизации, проверки прав, поиска файлов альбома. Плюс, там же будут работать мои и Django'вские middleware-фильтры. Короче говоря, я уже имею всю нужную инфраструктуру. Осталось написать только раздачу в сокеты.
Библиотечка asyncore оказалась довольно таки удобной. Все, что потребовалось от меня — это повесить свои функции на события "handle_read", "handle_write", "handle_close", которые библиотека сама запускает, когда сокеты готовы принимать и отдавать данные, и когда закрываются. В эти обработчики я свалил всю свою логику по откусыванию кусочков от файла и ограничению скорости. И даже разбор HTTP-запроса мне не пришлось писать самостоятельно, потому что с Медузой очень удачно поставляется пример HTTP-сервера, из которого я стащил все то немногое, что надо сделать перед тем, как сформировать Django'вский HttpRequest.
Кстати, после того, как я познакомился с Meduse/asyncore, я, опять же впервые для себя, наткнулся у Pythy на описание библиотечки Twisted, которая, похоже, умеет делать то же самое, но более развита. Это так? Где почитать?
В итоге, сервер где-то за неделю был написан и отлажен. И работал, выдерживая и по 100, и по 200 пользователей с неограниченным трафиком. При этом CPU загружался не больше, чем на 50-60% процентов в пике.
Что еще приятно, из-за того, что теперь весь код сервера был полностью в моих руках, удалось решить множество мелких и не очень проблем:
Раньше в итераторе приходилось записывать количество скачанных байт на каждой итерации, потому что по окончании передачи (удачном или неудачном) ничто не сигнализировало итератору о том, что надо что-то закрывать. Теперь, поскольку и саму передачу делаю я, я могу гарантировано знать ее окончание и делать всю статистику один раз в конце.
По той же причине я точно знаю, сколько байт передано, поэтому пропала нужда в сомнительном решении с фиксацией окончания скачивания на один шаг раньше его реального окончания (подробнее см. первую часть триллера).
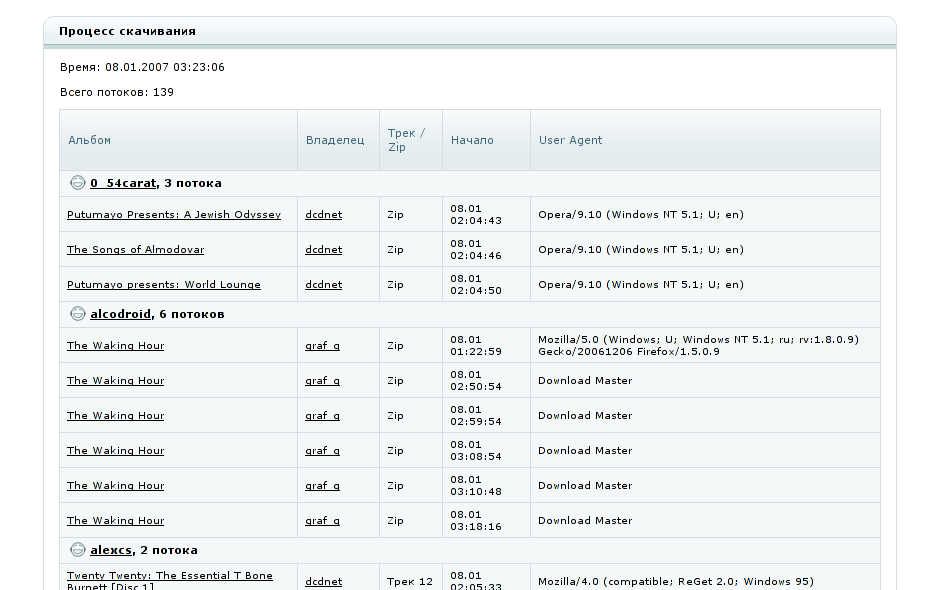
Особая вкусность: имея в одном процессе все соединения, я могу знать, какие пользователи что качают в данный момент и выдавать такую статистику:
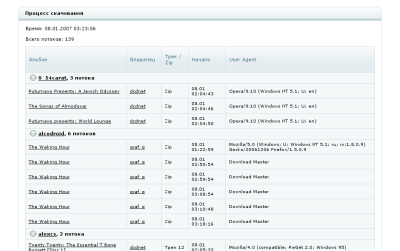
Сама страничка, кстати, рисуется все теми же Django'вскими шаблонами.
Тем не менее, все мы боялись того, что реальная нагрузка будет каким-нибудь образом отличаться от тестовой, и работать все это не будет. Но все наши страхи оказались напрасными :-). Сервис запущен, download server обслуживает всех, кто к нему обращается, причем процессор нагружает процентов на 30 независимо от того, 80 на нем пользователей или 180. Скушал около 35 МБ памяти и она там колышется в небольших пределах в зависимости от количества народу. Работает неделями без перезагрузки.
Красота!
Вот вам и сочинение "Как я провел лето" :-)
Комментарии: 59 (особо ценных: 1)
Восхитительно, однозначно!
Хоть несколько далековатая от меня область, но тем не менее прочитал на духу без остановки. И даже что то понял, и запомнил на будущее! Спасибо!
Статья понравилась. Ссылки на баги/тикеты не помешали бы, а то не понятно, какая версия lighttpd избавлена от бага... ;-)
Ну на русском языке только у меня ;-) На английском - есть документация и книга. Есть еще некоторое количество статей на onlamp и ibm.developerworks.
Вообще, про http-сервер на twisted писал Валентино Волонги ~1 ~2.
Если покажешь свой сервер на asyncore, я попробую сделать его на twisted, посмотришь...
Супер. Хоть я даже python практически не знаю и подобным программированием не занимался, теперь понимаю, как это может быть интересно :)
Версия была 1.4.11, но это не очень актуально, потому что баг этот не получил никаких комментариев и не исправлен: http://trac.lighttpd.net/trac/ticket/755
У lighttpd, как ни странно, вообще очень тяжко с исправлением бага. Я, кажется, два бага как минимум постил - ни один не был исправлен. :(
А у nginx обратная ситуация обычно бывает...
Кстати, интересно будет посмотреть, как с таким сможет справиться mongrel.
Да, к сожалению ни один готовый фреймворк для "долгой раздачи" файлов не подходит. У меня для этого есть захаченый thttpd, который пишет события в sqlite и питоновый скрипт, который очередь этих событий разбирает. Костыли и веревочки в общем.
Ну я тоже уже давно обещанную вторую часть ждал :)
Вышло как всегда интересно, познавательно, захватывающе и увлекательно. Жду новых постов про НМС.
Опечаточка:
Для сервиса 3mp3.ru очень давно делалась подобная система, только без ограничения по ширине канала.
Начали с отдачи фаликов при помощи хендлепа apache (mod_perl), продолжили написанием модуля для апаче на С. Ни то ни другое не удовлетворяло по скорости.
Тогда фалики стал отдавал tux сервер, работающий на уровне ядра, тогда помниться ни lighty ни nginx не жили.. или плохо искали.
Был написан к этому tux модуль, который авторизовал по ключу, открывал коннекты к БД, писал сколько скачено и тп...
Вообще я глубоко убежден, что раздача файлов, выполнение ресурсоемких операций не должна быть завязаны на фреймворк.
Тот же rails неблещуший скоростью, расчитан на отдачу веб страниц, в крайнем случай спасет кеш.
Вот, история получила достойный финал :) Я прочитал сначала первую часть истории, и хотел (пока не заметил, что тот пост весьма старый)написать комментарий, что проблему надо решать на другом уровне. Вижу, Вы до этого уровня и добрались :)
Приятно почитать, даже просто как рассказ :)
Имел в проекте 9 лет назад примерно те же проблемы, вылечившиеся как ни странно применением tclhttpd (мелкий серверок написанный на Tcl). Потому очень веселился с одной стороны, и с другой стороны корил себя за то, что никак не оформлю архитектурные наработки последних 15 лет хоть во что-то читабельное/грепаемое. Впрочем, ну его, кто это разыщет в нынешних-то завалах? :)
Сериал просто супер!
Сам сейчас занимаюсь подобной задачей, правда к своему стыду таких познаний не имею.
И пишу всё это дело на php.
Вот и подумалось - для php есть какойнить вариант решения? Отдаю файлы с авторизацией и докачкой средствами php. Пока нагрузка не большая, всё хорошо, но скора она будет гораздо больше.
Для Павла
за основу можно взять http://nanoweb.si.kz/ но поработать напильником придётся
Похоже, кастомные веб-сервера на nbIO рано или поздно приходится писать всем (:
Меня только удивляет, почему никто этим с миром не делится :-). Так, глядишь, и мне столько мучиться не пришлось бы :-)
Кстати, как выяснилось, в Ruby под Windows неблокирующих сокетов нет. 8-(
2 Алексей Захлестин
спасибо, почитаю
правда не уверен, что битрикс под этим запустится :) у меня всё еще ослажнено битриксом
2 Иван Сагалаев
есть такой чат на пхп от Димы Бородина
вот он какраз тоже делал для чата демона, который работает с сокетами, правда на tcl
исходников нет :( и проект умер
а идея была хорошая. при поддержке 200 одновременных пользователей, демон жрал всего 5 мегабайт памяти
2enternet: в виндвовсе их не сделали? Тогда, боюсь, для этого прийдется делать хитро выдрюченную систему, когда заводится пул нитей, каждая из которых ждет свой сокет и в центральной нити живет их менеджер, с которым уже руби общается.
спасибо большое за статью
буду рекомендовать ее в качестве наглядного пособия над тем, как человек сам учится тому как делать высоко нагруженные web-applications
История, как всегда, отличная, спасибо!
Но, просто для информации, если бы не требование отслеживать конец скачки (т.е. если бы вы продавали не факты скачивания, а, скажем, возможность скачивания в течение какого-то времени), то всё это можно было переложить на nginx. Он сам умеет и полосу пропускания ограничивать для нужных файлов, и отдавать файлы со скриптовой авторизацией… Только хвост ловить не умеет.
Да, и lighty тоже такое умеет. Но чего еще они не умеют (хотя я подробно не выяснял, может и ошибаюсь), так это ограничивать совокупную скорость скачивания для одного отдельно взятого пользователя. Причем, по IP-адресу пользователя определить в общем случае нельзя.
И кстати, отслеживание конца скачивания у нас тоже не тупое: человек может скачать альбом в виде автоматически собираемого zip'а, а может скачать отдельно по трекам. А может скачать пару треков, потом решить перескачать zip'ом. И во всех таких случаях окончание скачивания все равно отслеживается.
2 Павел: На чистом php задача не решается. Ну, то есть, можно писать на серверок на php (какие-то сокеты в нём есть), но это будет очень неудобно.
С учётом того, что у Вас Битрикс (который, кажется, без апача не живёт), я бы посоветовал поставить всё хозяйство (апач с php и битриксом) за nginx и научить его а) проксить динамику, б) самостоятельно отдавать статику и в) отдавать большие файлы с авторизацией через бэкенд. Но, как было сказано выше, отследить факт полной скачки при этом не удастся.
2 Иван Сагалаев: Да, мне как-то сходу в голову не приходит, как там правильно ограничить в канале пользователя.
2 Давид
у меня какраз продаётся доступ к файлу на 24 часа и факт скачивания не фиксируется, так что nginx подходит похоже
как ограничить число конектов с одной сессии nginx'ом понятно, а вот насчет ограничения скорость и авторизации через бекэнд - как-то не очень пока ясно
пытался сделать аналогичное обрезание скорости скачивания, как в первой части статьи, но на пхп такое не работает, хотя можт у меня руки кривые - отдаётся только первые 4 килобайта файла
Еще вопрос к автору немного не по теме.
Какие платежные системы прикручены к сайту и чем из них люди пользуются активнее?
2 павел:
http://blog.kovyrin.net/2006/11/01/nginx-x-accel-redirect-php-rails/lang/ru/
Наверное, это уже несколько оффтопик.
2 павел: а вот в контексте битрикса:
http://www.bitrixsoft.ru/support/articles/alexey_shtol.php
Нет слов, Иван! Обе статьи очень интересные, правда, да еще и затягивают похлеще иного детектива :)
Огромное спасибо вам за блог :)
Возможно, это статья по теме:
«Использование X-Accel-Redirect с Nginx для реализации контролируемых скачиваний (с примерами для rails и php)» — http://blog.kovyrin.net/2006/11/01/nginx-x-accel-redirect-php-rails/
Интересно конечно, хотя мне с самого начала было не понятно почему автор сразу не пошел по "верному пути". Я работаю с Twisted и использование сервера на неблокируемых сокетах мне кажется естественным решением. Наиболее позновательным для меня в данной работе стал раздел про "слепого котенка", не знал что за nginx есть такой косяк, теперь буду внимательнее.
Это что-же получается что на каждого пользователя
создается новый ПРОЦЕСС а не поток? Вроде же
Аппач(давно) и Джанго(от рождения) умеют потоки.
Или я чего-то не дочитал?
Это хороший вопрос :-).
Apache в тредном режиме запустить не получилось, потому что mod_php (который там тоже крутит что-то другое) требует именно prefork модель.
FastCGI-сервер я тоже пробовал запускать в тредном режиме, но по неизвестной причине он все равно плодил очень много отдельных процессов. Я не нашел уже сил и времени в этом разобраться, потому что это было под конец истории. В любом случае, неблокирующие сокеты для этой задачи (со всеми ее особенностями, ОС и Питоном) эффективней тредов.
Ууу. Фтопку mod_php ;)).
А не пробовали два сервака стартануть - один для
Пых-Пых не процессах а второй для Django на потоках?
Безусловно. Просто написание хорошего HTTP сервера довольно сложная задача, как Вы понимаете. Например как у Вас обстоят дела с кешированием данных (заголовки
if-Modifed-Since,Cache-Control,etc.)? Их
отсутствие или неправильная обработка приведет к
существенному повышению нагрузки на сервер из-за
повторного вынимания уже загруженных данных.
Это так-же не позволит нормально работать Squid
и другим кеширующим прокси серверам.
Поддерживаете ли Вы keep-alive и
http-pipelining? Если нет то это тоже модет
заметно повысит нагрузку на пустом месте.
Хотя как раз в Вашем случае это все и не нужно.
Я долгое время делал на питоне несколько
обратную задачу - модуль HTTP лоадера и
столкнулся с этими проблемами.
Уппс.
Именно. Сервер крайне специфичен. Пользователь качает один большой файл, который вряд ли будет запрашивать повторно — кеширование не нужно (а то и вредно). И у этого файла нет сопутствующих запросов всякой media, поэтому не нужен keep-alive и pipelining.
А как эти заголовки могут контролироваться Apache когда он работает с fcgi или mod_python или еще чем? Это полностью прерогатива скриптов. Или я ошибаюсь?
А почему вы не попробовали проксировать запросы с Apache (или еще чего) на Django сервер?
Проксирование я пробовал, забыл написать только. Проксирование через Apache еще больше ухудшает ситуацию, потому что тогда на каждый запрос в памяти висят два тяжелых процесса: FastCGI, который занимается скачиванием, и проксирующий Apache, который не делает ничего, кроме ожидания ответа от FastCGI.
FastCGI тут не причем. Вы вешаете Django, скажем, на порт 8080 (manage.py runserver 8080) и передаете на него запросы с Apache/nginx (с lighttp не работал). Вот пример настройки nginx:
server {
listen 80;
server_name example.com;
Теперь лишь остается проблема настройки фроненд сервера (Apache/nginx).
FastCGI тут все таки причем... Во-первых, Django — это не HTTP-сервер, поэтому на него нельзя проксировать HTTP. Поэтому Django поднимается как FastCGI-сервер. Но это бы и ладно, без разницы какой там протокол. Но суть проблемы в том, что Django — это не один процесс, это много процессов, и они будут долгими, и будут занимать память. Ключевое слово — долгими. Весь веб работает хорошо только потому, что толстый процесс очень быстро обрабатывает короткие запросы, поэтому в секунду может обработать их сотни, и поэтому таких процессов нужно сравнительно немного. Если же запросы многочасовые, то вся эта традиционная схема ломается.
И как я уже сказал, что поставить фронтендом — тоже имеет значение. Если это Apache, то он тоже будет форкнут на каждый текущий запрос, и тоже будет есть памяти сравнимо с бэкенд-процессами. Поэтому легким фронтендом Апач не может быть никогда.
А схемы lighttpd-FastCGI и nginx-FastCGI я подробно описал, почему не работали.
Иван, Вы гений. Преклоняюсь перед Вашим терпением и целеустремленностью! Статьи просто супер (как, впрочем, и всега)! Так держать! С нетерпением жду изложения Ваших следующих изысканий :-)
Вот когда человек называет twisted "библиотечкой" - сразу понятно что у его ожидают проблемы подобные описанным в этой статье ;-)
А статья отличная, спасибо.
Особо ценный комментарий
Я уже много лет занимаюсь разработками именно в области неблокирующего I/O, правда на Perl. Так что могу рассказать где следующие грабли лежат на этой тропе. ;-)
Во-первых asyncore использует select() или poll(), а они при большой нагрузке начинают тормозить. Для решения этой проблемы я линухе 2.6 добавили epoll(7), в BSD есть всякие kqueue, etc.
Во-вторых кол-во файловых дескрипторов на процесс обычно ограничено 1024, и изменить (увеличить) это может только root. Впрочем это обычно не большая проблема, т.к. сервера которым нужно обрабатывать больше тысячи клиентов обычно запускаются на своём дедике.
Вот классическая ссылка по теме: http://www.kegel.com/c10k.html
Это что касается сервера. Для клиента есть ещё такие грабли как DNS - чтобы качать сотнями/тысячами потоков с разных серверов (есть и такие задачки :-)) нужно уметь быстро и асинхронно ресолвить их IPшники.
А вообще всё описанное в статье по духу звучит очень знакомо. Суть в том, что "шаг влево, шаг вправо" от простеньких типовых задач, и начинаются такие минные поля из грабель... Причём везде - ядро, glibc, сервер бд, веб сервер, а уж про используемые стандартные библиотеки языка и фреймвёки я просто молчу.
Возможно, для отдачи файла подойдет связка nginx+apache. Например, на бэкенде после авторизации отдать хедеры:
X-Accel-Limit-Rate: 12345
X-Accel-Redirect: /download/file.mp3
а в nginx:
location ^~ /download/ {
internal;
root /blah/
post_action /blahblah.php;
}
http://search.gmane.org/?query=X-Accel-Redirect+%D0%B7%D0%B0%D0%BA%D0%B0%D1%87%D0%BA%D0%B0+%D0%B7%D0%B0%D0%B2%D0%B5%D1%80%D1%88%D0%B5%D0%BD%D0%B0&author=&group=gmane.comp.web.nginx.russian&sort=relevance&DEFAULTOP=and&TOPDOC=40&xP=post%09action&xFILTERS=Gcomp.web.nginx.russian---A
Не знаю насколько такое решение работает в плане многопоточной загрузки... но в любом случае быстро, поскольку бэкенд, отдав заголовки, может спокойно на время загрузки закрыться :)
А как отслеживается, что файл действительно получен ? Если мы отправили всё, это еще не значит что клиент всё получил.
А это, судя по всему, невозможно отследить принципиально: между сервером и клиентом может сидеть какой-нибудь прокси, который тоже теоретически может все взять и не отдать. Но на практике получается, что "отправлено" и "получено" совпадают в большинстве случаев.
Можно поинтересоваться, с помощью чего вы тестировали нагрузку для asyncore?
Сначала написал очень тупой скрипт, который создавал N тредов, в которых делал urlopen одного и того же файла. А потом — просто пользователи стали приходить.
Вы здорово постарались, и хорошо разобрались во всем этом.
Тем не менее, зачем это все надо? У вас платный сервис? Если да, то зачем ограничивать скорость скачивания? Пускай юзер поскорее заберет то, за что заплатил, и закажет еще. Вы же тратите время и силы на то, чтобы добавить ему препятствий.
Суммарная загрузка все равно будет такая же: все, что куплено, будет скачано. Я говорю про тот случай, когда у вас помегайбайтная или пофайловая оплата.
Если же у вас некий вариант безлимитки, когда юзер платит например за сутки, можно ограничить суммарное количество мегабайт.
Просто обалденная статья столько опыта, страсти и юмора!
Ваши посты просто толкают питонить, питонить и питонить! ;*) Правда не знаю с чего начать(я PHP программист). Может, посоветуете какую-нибудь печатную литературу? Потом конечно попробую Django. Спасибо большое очень интересно!
P.S. Однозначно — триллер!
Dive Into Python. К сожалению, русской версии нету полной, не то что печатной... Но книга отличная. А из русского печатного хороша довольно книга Романа Сузи, но её ещё найти надо.
Спасибо очень хорошая статья
Сделал тоже самое на php и был очень недоволен (использовал pecl-http). Сегодня же ночью засяду переписывать на питоне)
Виктор, а если я скажу, что подобное можно сделать на Perl (POE, IO::Async, Event), вы будете переписать на Perl? :)
Занимательно, действительно, маниакальный блог )))
Хорошая реклама Python получается.
Рискую опять стать жертвой чтения в хронологическом порядке, но почему бы не поделиться с миром вашими наработками? :)
P.S. Спасибо за статью. Прекрасное завершение первой части - все встало на свои места, как в хорошем детективе.
Добрый день. Спасибо за статью, очень познавательно. Но вот один момент непонятен:
Вы внутрь своего сервера на медузе вставили джангу ? Или в джангу вставили свой сервер? Или может они работают независимо? Не могли бы в 2-х словах рассказать как вы их скрещивали. Заранее спасибо.