Вдогонку статье о неоднозначной судьбе XHTML'а на вебе я обещал написать, как может из одного исходного текста получиться два разных DOM-дерева, в зависимости от того, как исходник трактовать: HTML или XHTML.
Исходник
Итак предположим, вы решили разметить документ с помощью XHTML таким образом, что для тех потребителей, которые понимают XHTML, он выдается в этом виде, а для тех, кто не понимает — в виде HTML. Это, кстати, довольно легко реализуется: достаточно проверить, есть ли в HTTP-заголовке Accept, в котором потребитель перечисляет допустимые для себя типы, application/xhtml+xml и отдать содержимое с этим типом или с text/html, если нет.
Исходный текст таков:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Тест</title>
</head>
<body>
<h1>Сравнение апельсинов и яблок</h1>
<table>
<tr>
<td>Апельсины - отстой!</td>
<td>Яблоки - вещь!</td>
</tr>
</table>
<address>
<p>Автор: Такой Т.О.</p>
<ul>
<li>EMail: takoy@megacorp.kk</li>
<li>Сайт: www.megacorp.kk</li>
</ul>
</address>
</body>
</html>
Этот код может восприниматься браузером и как XHTML, потому что он well-formed XML и имеет XHTML'ный namespace, и как HTML, потому что в нем нет несовметимых с HTML XML'ных конструкций.
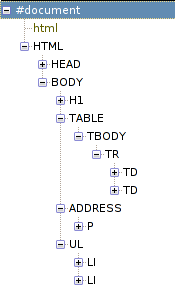
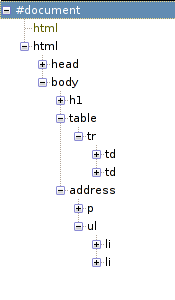
Я у себя сохранил этот код в файлы с расширениями "html" и "xhtml" и скормил Firefox'у, после чего для каждого снял дерево, которое показывает DOM Inspector. Вот что вышло:
| HTML | XHTML |
|---|---|
| 
|
Налицо различия. Сразу бросается в глаза, что имена элементов в разных регистрах. Но это, в общем-то, зло самое маленькое, потому что строки всегда можно сравнивать без учета регистра. А вот другие два интересней.
TBODY
В HTML-варианте у элемента TABLE появился ребенок TBODY, в котором уже завернуты строки и ячейки. И что интересно, он там и должен быть! Просто в HTML у элемента TBODY и открывающий, и закрывающий теги — опциональны, и его присутствие определяется по окружающему содержимому. В частности, конструкция элемента TABLE такова, что в валидном HTML TR не могут лежать прямо в нем, и поэтому для них создается TBODY неявно.
В XHTML такого понятия, как неявно присутствующие теги, нет вообще. Поэтому для него встает выбор: либо обязать всех всегда явно вписывать тег tbody, либо сделать его полностью опциональным. Выбрали, очевидно, второе, потому что к первому никто не привык, и делать бы все равно не стал.
UL в ADDRESS
В этом случае HTML и XHTML сходны в своем синтаксисе: элемент ADDRESS содержать UL не может. И поэтому в HTML'ном примере, как только появляется UL, ADDRESS тут же неявно закрывается.
В XHTML, по идее, такое нарушение валидности должно было стать фатальной ошибкой. Но, как я уже много раз поминал, все браузеры используют невалидирующий режим парсинга, и поэтому в XHTML-режиме дерево строится в точности, как написаны теги.
Тут, кстати, есть еще один интересный момент. Почему браузеры не делают валидацию XHTML, но делают валидацию HTML, которая сложнее. На самом деле, никакой честной валидации HTML по DTD-файлам браузеры не делают тоже, все это HTMLное как бы валидное поведение просто зашито в коде! А все из-за того, что браузеру надо соблюдать совместимость не с формальным синтаксисом, а с реальным HTML на вебе, который писался под разные старые браузеры и изобилует многочисленными странностями, на которые, тем не менее, полагаются веб-авторы.
В итоге
В итоге, если вы поддерживаете реальную XHTML страницу, совместимую с HTML, то надо быть очень осторожным при работе с DOM. Например, если в скрипте надо по известному TD найти его таблицу, то в HTML надо написать:
td.parentNode.parentNode.parentNode
... а в XHTML:
td.parentNode.parentNode
Но раз вам надо и то, и другое, то придется написать некую обертку, которая будет проверять имена тегов.
Такие, вот, трудности...
Комментарии: 18
собственно здесь: http://www.w3.org/TR/xhtml1/#C_11 об этом и написано
Пример-бы хотелось увидеть, где различия реальны.... тэг address и таблицы мне никогда не приходилось обращатся к ним через DOM... Другое дело фреймы и слои.
Если «в XHTML такого понятия, как неявно присутствующие теги, нет вообще», то откуда в address-е взялся ?
Сорри, «взялся
»?
Млин, наконец то доперло, откуда вылезают эти TBODY при сохранении страниц на диск, когда эти теги отсутствуют в исходном коде страниц, который генерирует PHP.
Давид, спасибо, я когда писал, потом дописал еще и
, а в статью новую версию скопировать забыл. Поправил.
Использование тега tbody уже давно вошло в привычку у меня. Вместе с thead и tfoot он позволяют намного гибче манипулировать внешним видом таблицы посредством css.
Не скажу что глаза раскрылись - о неявном присутствии tbody узнал довольно давно(как раз напоровшись на грабли с parentNode.parentNode) (на thead тоже натыкался при попытке таблица.cloneNode(true) ) . Другое дело, что пока
самый лучший браузер на планете"тупой" IE не научиться понимать "application/xhtml-xml" все поползновения делать "правильно" идёт лесом (через поле) - занимаясь "очень посещаемыми" сайтами для категории пользователей из разряда "видел 3 раза компьютер в школе(у друга, на выставке)[нужное_подчеркнуть]" собрал статистику с этих самых сайтов - 90% - IE ниже 6-ой версии, 9.7% - 6-ая версия IE и остаток (небольшой ;o) ) - "альтернативные браузеры" - стоит ли ради 0.1% добавлять иконку "ну очень валидно с какой стороны не глянь" на эти сайты? - чисто практически это возможно, после некоторой практики верстать станет даже легче(я сам вёрсткой не занимаюсь, но в плане "игр в DOM" непосредственно общаться приходиться очень часто).Так что вся судьба XHTML на данный момент в руках незабвенного M$. А они, судя по IE7beta особенно не горят сделать "революцию".Ни один FF, с его "мега-рекламой" не переломят инертность 90% пользователей, которые используют интернет в качестве средства работы(а не источника заработка).
td.parentNode.parentNode.parentNode
крайне не рекомендую использовать подобные конструкции вообще, ибо тем самым вы привязываетесь к конкретной структуре. а что если потребуется изменить структуру? бежать менять все скрипты?
так что этот аргумент - мимо кассы совершенно.
dark-demon
А что, везде тыкать "id = ..."? И тут дело не в том, что так пользовать нужно, а в том, что для html и xhtml нужно учитывать разные принципы построения DOM'а.
нет, id нужно юзать только там, где он действительно нужен. хотя, да, id позволяют абсолютно не зависеть от структуры :)
ps: ес-сно нужно учитывать, только автор не это хотел сказать, а хотел сказать он, что XHTML - отстой потому, что не полностью совместим с HTML.
Пожалуйста, не нужно приписывать мне того, чего я не говорил. Собственно, бо́льшая часть Ваших последних комментариев — чистейший strawman argument.
ты используешь "несоответствие дома между HTML и XHTML" в качестве аргумента против XHTML в соседней ветке. мол, либо ие не поддердивает, либо скрипты браузерозависимы, и всё из-за этого гадкого XHTML...
var obj=td;
while(obj.tagName.toUpper()!='TABLE') obj=obj.parentNode;
что мешает написать так?
а предложенный код совершенно некорректен по определению, тем более, в случае с таблицами.
да и tbody должен быть всегда, это должно войти в привычку. его отсутствие создает массу проблем.
Ничто не мешает. Моя основная мысль не в том, что это как-то невозможно или страшно трудно. Просто, это добавляет дополнительный уровень сложности (в системном смысле), а для этого нужна веская причина. Веской причины для подавляющего большинства веб-страниц просто нет.
веская причина - это то, что это пишется на яваскрипт-)
и то что реаличается как сам интерпретатор js так и страницы, которых, к тому же ещё куча видов и подвидов, у разных браузеров и даже разных версий браузеров.
это формирует определенные требования к коду, в частности, использование наиболее универсальных конструкций в спорных или даже потенциально спорных моментах.
да и никакого усложнения тут я не вижу. более того, так даже читаемость повышается - сразу понятно что мы ищем table.
я бы и вот так не постеснялся написать(если конечно это не единственный скрипт в пару строчек на странице и можно себе позволить prototype включить)
var table=$(td).ancestors().find(function(el){ return el.tagName.toUpperCase()=='TABLE'; })
да и вообще не должен яваскрипт быть привязан так к странице, это создает массу проблем. шаблон может делать/менять вообще другой человек.
Мне очень нравится подход автора.
Уважаемые коллеги давайте понимать, что то что нужно качественному продукту не нужно большинству страниц. Конечно, можно считать что большинство быдло тупое, а мы боги нашего дела, НО их большенство и они влияют на рынок. Поэтому давайте думать над тем как нам жить. А нам незачем просто все делать на XHTML (хотя отдельные примеры очень оправданы: теор аспект, целевая аудитория, стандартизация) просто давайте поймем, что HTML еще долго будет жить и примем его!